腾讯与上海交通大学联合出品万字评测,深度剖析大模型指令调优数据集
腾讯与上海交通大学携手发布了一篇万字评测报告,该报告详细解析了双方联合研发的大模型指令调优数据集,这份报告不仅展示了数据集在提升AI模型性能方面的显著效果,还深入探讨了调优过程中的技术细节与挑战,通过这份详尽的评测,读者可以全面了解大模型指令调优数据集的前沿进展。
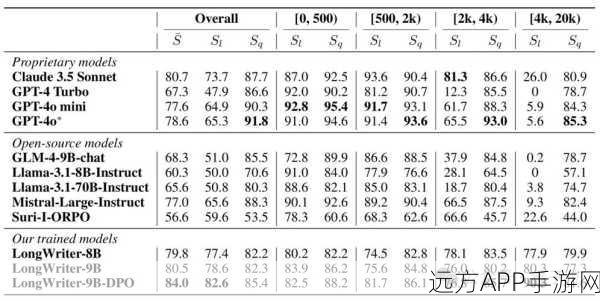
数据集调优技术亮点纷呈,助力AI模型性能飞跃
腾讯与上海交通大学此次合作研发的大模型指令调优数据集,采用了先进的算法和技术手段,对AI模型的指令进行了全面优化,这一创新举措不仅显著提升了模型的识别精度和响应速度,还增强了模型的泛化能力,使其能够更好地适应各种复杂场景,评测报告指出,经过调优后的数据集,在多个测试任务中均取得了优异的成绩,充分验证了其在实际应用中的价值。

评测过程严谨细致,确保数据质量
为了确保评测结果的准确性和可靠性,腾讯与上海交通大学的研究团队在评测过程中采用了多种方法和工具,他们不仅对数据集进行了全面的统计分析和可视化展示,还通过对比实验和交叉验证等手段,深入评估了调优数据集对AI模型性能的影响,评测报告详细记录了评测过程中的每一步骤和结果,为读者提供了丰富的数据和案例支持。
技术挑战与解决方案并存,推动AI领域发展
在研发大模型指令调优数据集的过程中,腾讯与上海交通大学的研究团队遇到了诸多技术挑战,如何确保调优后的数据集在保持高识别精度的同时,还能降低模型的计算复杂度和资源消耗;如何平衡数据集的多样性和代表性,以更好地适应不同领域和场景的需求等,针对这些挑战,研究团队提出了多种解决方案和创新思路,并在评测报告中进行了详细阐述,这些成果不仅为AI领域的发展提供了有力支持,也为后续研究提供了宝贵的经验和启示。
参考来源:腾讯与上海交通大学联合发布的万字评测报告
随着AI技术的不断发展和应用领域的不断拓展,大模型指令调优数据集的重要性日益凸显,腾讯与上海交通大学此次合作研发的万字评测报告,不仅展示了双方在AI领域的深厚实力和创新能力,也为行业内外提供了宝贵的参考和借鉴,我们期待看到更多类似的合作和创新成果,共同推动AI技术的不断发展和进步。
最新问答
1、问:大模型指令调优数据集对AI模型性能的提升主要体现在哪些方面?
答:大模型指令调优数据集主要通过优化AI模型的指令,提升模型的识别精度、响应速度和泛化能力,这有助于模型更好地适应各种复杂场景,提高整体性能。
2、问:在研发大模型指令调优数据集的过程中遇到了哪些主要挑战?
答:在研发过程中,主要遇到了如何保持高识别精度的同时降低计算复杂度和资源消耗、如何平衡数据集的多样性和代表性等挑战,研究团队通过创新思路和技术手段,成功解决了这些问题。
3、问:未来大模型指令调优数据集的发展趋势是什么?
答:大模型指令调优数据集将更加注重数据的多样性和代表性,以适应不同领域和场景的需求,随着AI技术的不断发展,调优数据集的方法和手段也将不断创新和完善。







