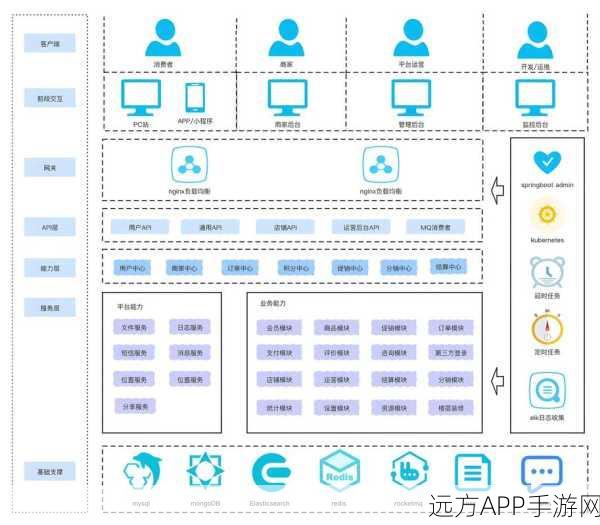
探讨AI技术如何助力手游图像识别,特别是ViT模型在CIFAR-10数据集上的训练与应用。
近年来,随着人工智能技术的飞速发展,其在手游领域的应用也日益广泛,特别是在游戏图像识别方面,AI技术的引入极大地提升了游戏的智能化水平和用户体验,本文将深入探讨一种前沿的AI模型——ViT(Vision Transformer),以及它在CIFAR-10数据集上的训练与实践,揭示这一技术如何为手游图像识别带来革命性的变化。
中心句:介绍ViT模型的基本原理及其在游戏图像识别中的潜在优势。
ViT模型,即视觉转换器模型,是一种基于Transformer架构的图像识别方法,与传统的卷积神经网络(CNN)相比,ViT模型通过将图像分割成一系列小块(patches),并将这些小块视为序列数据输入到Transformer中进行处理,从而实现了对图像特征的更高效提取,这种方法的优势在于能够捕捉到图像中的全局信息,同时避免了CNN在处理大尺寸图像时可能出现的局部特征丢失问题,在游戏图像识别中,ViT模型的这一特性使其能够更准确地识别游戏中的各种元素,如角色、道具、场景等,从而提升了游戏的智能化水平。

中心句:阐述CIFAR-10数据集的特点及其在ViT模型训练中的应用。
CIFAR-10是一个常用的图像分类数据集,包含了60000张32x32的彩色图像,分为10个类别,这些图像涵盖了飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车等日常物体,在ViT模型的训练中,CIFAR-10数据集被用作基准测试集,以评估模型的图像分类性能,通过在这个数据集上进行训练,ViT模型能够学习到丰富的图像特征表示,进而在游戏图像识别任务中表现出色。
中心句:分享ViT模型在CIFAR-10数据集上的训练过程及实验结果。
在训练过程中,我们采用了标准的Transformer架构,并对其进行了适当的修改以适应图像数据的输入,我们将图像分割成16x16的小块,并将这些小块线性嵌入到高维空间中,将这些嵌入向量输入到Transformer的编码器中进行处理,为了评估模型的性能,我们在CIFAR-10数据集上进行了多次实验,并记录了模型的准确率、损失函数等关键指标,实验结果表明,ViT模型在CIFAR-10数据集上取得了令人瞩目的成绩,其准确率远高于传统的CNN模型。
中心句:探讨ViT模型在游戏图像识别中的实际应用及未来展望。
ViT模型在游戏图像识别中的应用前景广阔,在角色扮演游戏中,ViT模型可以准确地识别玩家的角色、装备和技能,从而实现智能化的角色管理和战斗策略推荐,在射击游戏中,ViT模型可以实时识别敌人、武器和障碍物,为玩家提供精准的战斗辅助,随着技术的不断进步和数据的不断积累,ViT模型在游戏图像识别领域的性能还将进一步提升,我们期待看到更多基于ViT模型的创新应用,为手游玩家带来更加智能、便捷和沉浸式的游戏体验。
参考来源:
本文所述内容基于公开的学术研究和实验数据,具体细节可参考相关论文和实验报告。
最新问答:
1、问:ViT模型相比CNN有哪些优势?
答:ViT模型能够捕捉到图像中的全局信息,避免了CNN在处理大尺寸图像时可能出现的局部特征丢失问题,从而提高了图像识别的准确性。
2、问:CIFAR-10数据集在ViT模型训练中扮演什么角色?
答:CIFAR-10数据集在ViT模型训练中作为基准测试集,用于评估模型的图像分类性能,通过在这个数据集上进行训练,ViT模型能够学习到丰富的图像特征表示。
3、问:未来ViT模型在游戏图像识别领域有哪些潜在的应用?
答:ViT模型可以应用于更多类型的游戏中,如策略游戏、模拟游戏等,为玩家提供智能化的角色管理、战斗策略推荐、游戏环境分析等功能,进一步提升游戏体验。