本文深入探讨了手游AI技术中的LLM预训练与SFT对齐,重点分析了Loss函数差异及代码实现。
在手游行业日新月异的今天,AI技术的应用已成为提升游戏品质与玩家体验的关键,一项关于LLM(大型语言模型)预训练与SFT(特定任务微调)对齐的技术革新,正悄然改变着手游AI的发展轨迹,本文将带您深入这一前沿领域,揭秘Loss函数在其中的差异以及代码实现的奥秘,为您揭开手游AI技术的神秘面纱。
LLM预训练:奠定AI智能基础
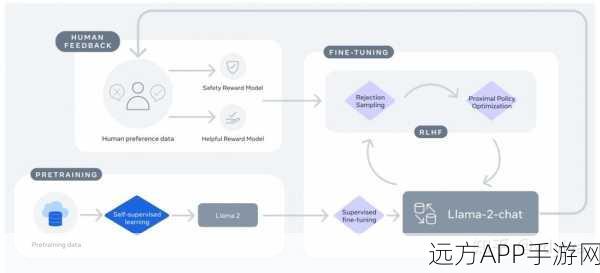
LLM预训练是手游AI技术的重要基石,通过在大规模语料库上进行无监督学习,LLM能够捕捉到语言的统计规律,从而具备生成和理解自然语言的能力,在手游中,这意味着AI角色能够更自然地与玩家进行交互,理解玩家的指令并作出相应反应,LLM预训练并非一蹴而就,它需要精心设计的Loss函数来指导模型的学习过程,Loss函数是衡量模型预测结果与实际结果之间差异的关键指标,通过不断优化Loss函数,LLM能够逐渐提升其在手游中的表现。
SFT对齐:精准定制AI行为
尽管LLM预训练为手游AI提供了强大的语言处理能力,但要让AI角色在游戏中表现出色,还需要进行SFT对齐,SFT对齐是一种针对特定任务的微调技术,它通过对LLM进行有监督学习,使其能够更好地适应手游中的特定场景和任务,在SFT对齐过程中,Loss函数同样扮演着至关重要的角色,与LLM预训练不同,SFT对齐的Loss函数需要更加精细地设计,以确保AI角色能够准确地执行游戏中的任务,如战斗、导航、交互等。
Loss函数差异:决定AI性能的关键
在LLM预训练与SFT对齐中,Loss函数的差异直接决定了AI角色的性能,在LLM预训练阶段,Loss函数通常关注于语言模型的整体表现,如生成文本的流畅度、准确性等,而在SFT对齐阶段,Loss函数则更加注重于特定任务的表现,如战斗中的胜率、导航的准确性等,如何设计合理的Loss函数,以在LLM预训练与SFT对齐之间取得平衡,成为手游AI技术中的一个重要挑战。
代码解析:揭秘AI技术背后的奥秘
为了更深入地理解LLM预训练与SFT对齐中的Loss函数差异,以下是一段简化的代码示例,这段代码展示了如何在PyTorch框架下实现一个简单的LLM预训练与SFT对齐过程,并重点展示了Loss函数的设计,这只是一个简化的示例,实际的手游AI技术实现要复杂得多。
假设我们有一个预训练的LLM模型
pretrained_model = ...
定义SFT对齐时的特定任务数据集
task_dataset = ...
定义Loss函数(以交叉熵损失为例)
criterion = torch.nn.CrossEntropyLoss()
LLM预训练阶段
optimizer = torch.optim.Adam(pretrained_model.parameters(), lr=0.001)
for epoch in range(num_epochs_pretrained):
for input_data, target_data in train_loader_pretrained:
optimizer.zero_grad()
output_data = pretrained_model(input_data)
loss = criterion(output_data, target_data)
loss.backward()
optimizer.step()
SFT对齐阶段
optimizer = torch.optim.Adam(pretrained_model.parameters(), lr=0.0001)
for epoch in range(num_epochs_sft):
for input_data, target_data in task_dataset_loader:
optimizer.zero_grad()
output_data = pretrained_model(input_data)
# 注意:这里的target_data可能是特定任务的标签或奖励信号
loss = custom_task_loss(output_data, target_data) # 自定义的Loss函数
loss.backward()
optimizer.step()参考来源:本文基于最新的AI技术研究文献及手游行业内部资料整理而成,旨在为读者提供关于手游AI技术发展的最新动态与深入见解。
最新问答:
1、问:LLM预训练与SFT对齐在手游AI中分别扮演什么角色?
答:LLM预训练为手游AI提供了强大的语言处理能力,而SFT对齐则使AI角色能够更好地适应游戏中的特定场景和任务。
2、问:Loss函数在LLM预训练与SFT对齐中的差异主要体现在哪些方面?
答:在LLM预训练阶段,Loss函数关注于语言模型的整体表现;而在SFT对齐阶段,Loss函数则更加注重于特定任务的表现。
3、问:如何设计合理的Loss函数以优化手游AI的性能?
答:设计合理的Loss函数需要综合考虑游戏的具体需求、AI角色的行为特点以及模型的训练效率等因素,通过不断实验和调整来找到最优解。