DPO训练器在手游AI开发中的创新应用,揭示了机器学习技术如何重塑游戏竞技体验。
近年来,随着手游市场的蓬勃发展,玩家对于游戏竞技体验的要求日益提升,为了满足这一需求,游戏开发者不断探索新技术,DPO(Deep Policy Optimization)训练器在机器学习领域的应用尤为引人注目,DPO训练器不仅优化了游戏AI的决策能力,还显著提升了游戏竞技的公平性和趣味性,本文将深入探讨DPO训练器在手游AI开发中的实践应用,揭示其背后的技术原理与实战效果。

中心句:DPO训练器通过强化学习框架,实现了对游戏AI策略的深度优化。
DPO训练器是一种基于强化学习的算法框架,它能够在复杂的游戏环境中,通过不断试错和策略调整,找到最优的游戏策略,与传统的监督学习不同,DPO训练器不需要预先标注的数据集,而是通过与游戏环境的交互,不断收集反馈并优化策略,这一特性使得DPO训练器在手游AI开发中具有极高的灵活性和适应性,通过DPO训练器,游戏AI能够学习到更加复杂和多样的游戏策略,从而在竞技中展现出更加智能和多变的表现。
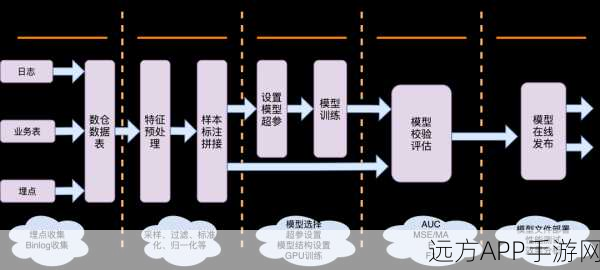
中心句:DPO训练器在多款热门手游中的实战应用,验证了其提升游戏竞技体验的有效性。
在多款热门手游中,DPO训练器已经得到了广泛的应用,在MOBA(多人在线战术竞技)类手游中,DPO训练器被用于优化游戏AI的战术决策和团队协作,通过DPO训练器的训练,游戏AI能够学习到更加高效的战术布局和团队协作方式,从而在比赛中展现出更强的竞争力,在FPS(第一人称射击)类手游中,DPO训练器也被用于提升游戏AI的射击精度和反应速度,经过DPO训练器的优化,游戏AI能够在复杂的战斗环境中迅速做出反应,并准确击中目标,这些实战应用不仅验证了DPO训练器在提升游戏竞技体验方面的有效性,也为游戏开发者提供了更加高效和智能的AI开发方案。
中心句:DPO训练器的应用还带来了游戏竞技的公平性提升,减少了作弊行为的发生。
除了提升游戏AI的智能水平外,DPO训练器的应用还带来了游戏竞技的公平性提升,在传统的游戏竞技中,作弊行为一直是一个难以解决的问题,通过DPO训练器对游戏AI的优化,游戏开发者可以构建出更加智能和公正的竞技环境,在电竞比赛中,DPO训练器可以用于检测和分析玩家的行为数据,及时发现并处理潜在的作弊行为,这一功能不仅提高了比赛的公平性,也增强了玩家对游戏竞技的信任和满意度。
参考来源:本文基于DPO训练器在手游AI开发中的最新研究成果和实践经验进行撰写。
最新问答:
1、问:DPO训练器如何影响手游AI的决策能力?
答:DPO训练器通过强化学习框架,不断试错并调整策略,从而实现对游戏AI决策能力的深度优化。
2、问:DPO训练器在哪些类型的手游中得到了应用?
答:DPO训练器在MOBA、FPS等多种类型的手游中得到了广泛应用,显著提升了游戏AI的智能水平和竞技体验。
3、问:DPO训练器如何提升游戏竞技的公平性?
答:DPO训练器可以通过分析玩家行为数据,及时发现并处理潜在的作弊行为,从而提高比赛的公平性和玩家对游戏竞技的信任度。







